# A tibble: 33 × 3
wbc ag time
<int> <fct> <int>
1 2300 present 65
2 750 present 156
3 4300 present 100
4 2600 present 134
5 6000 present 16
6 10500 present 108
7 10000 present 121
8 17000 present 4
9 5400 present 39
10 7000 present 143
# ℹ 23 more rowsSurvival Models (MATH3085/6143)
Chapter 7: Survival Regression Models
22/10/2025
Fitting Cox models using R (gehan)
The R code below create survival curves. The argument newdata allows us to specify values of the explanatory variables. In this case there is one explanatory variable which can take two values. So we compute two survival curves for those two values. For comparison, the Kaplan Meier survival curves are also plotted in grey.
par(family = "Latin Modern Roman 10", mar = c(5.1, 4.1, 0.5, 2.1))
gehan.S <- survfit(gehan.cox, newdata = data.frame(treat = c("control", "6-MP")))
gehan.km <- survfit(Surv(time, cens) ~ treat, data = gehan)
plot(gehan.S, ylab = "Survival function", xlab = "Time", lty = c(2,1))
lines(gehan.km, lty = c(1,2), col = 8)
legend("topright", lty = c(1, 2, 1, 2), col = c(1, 1, 8, 8),
legend = c("6-MP (Cox)","Control (Cox)","6-MP (KM)","Control (KM)"), cex = 0.8)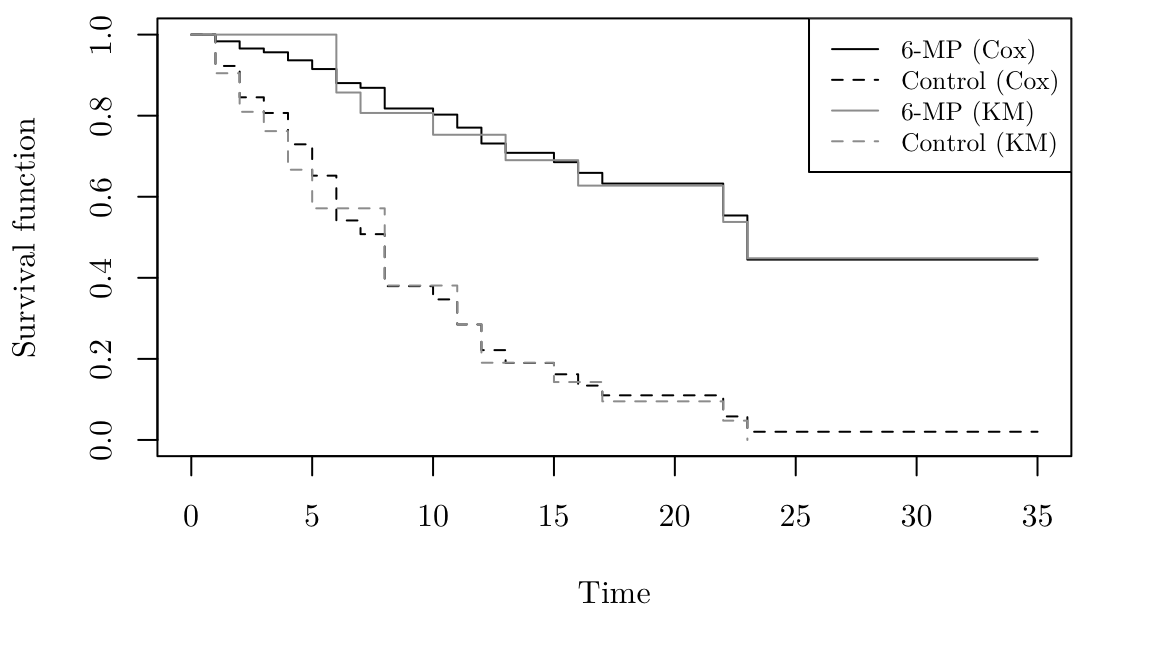
Fitting Cox models using R (leuk)
Similarly to before, we can plot the estimated survival functions as follows.
par(family = "Latin Modern Roman 10", mar = c(5.1, 4.1, 0.5, 2.1))
leuk.S <- survfit(leuk.cox, newdata = data.frame(ag = c("present", "present", "absent", "absent"),
wbc = c(750, 100000, 750, 100000)))
plot(leuk.S, ylab= "Survival function", xlab = "Time", lty = c(1, 2, 1, 2), col = c(1, 1, 8, 8))
legend("topright", lty = c(1, 2, 1, 2), col = c(1, 1, 8, 8),
legend = c("Present (750)", "Present (100,000)","Absent (750)", "Absent (100,000)"), cex = 0.8)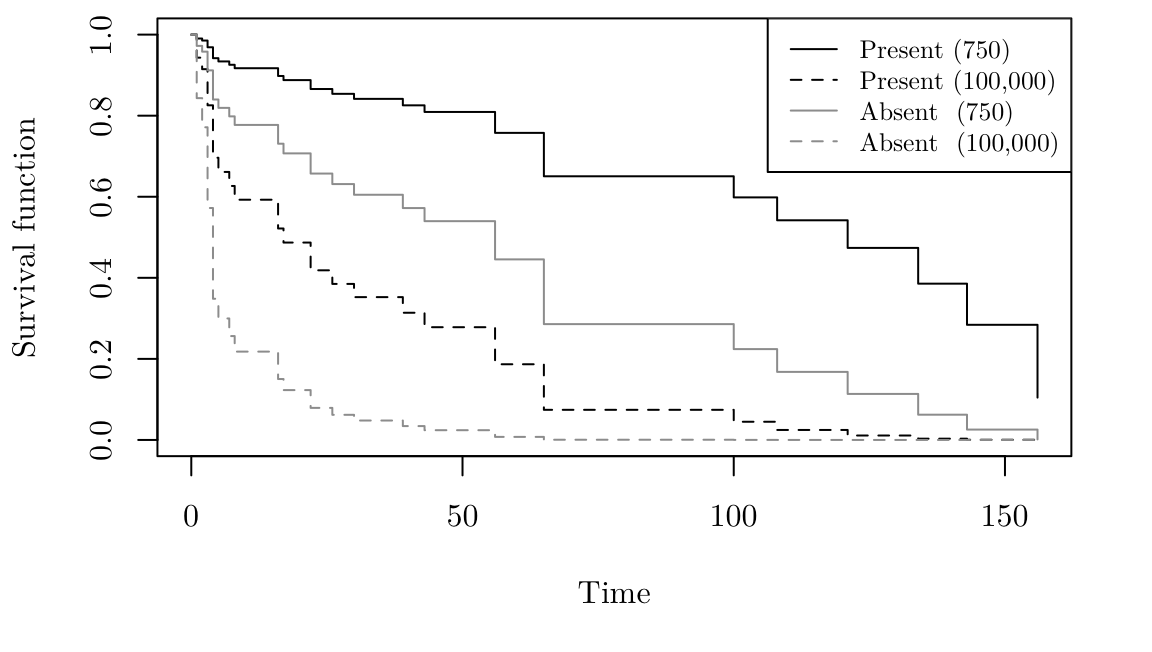
Checking proportional hazards
The following R code produces the plot for the gehan dataset, where \(x_j\) corresponds to treat.
logmlog <- function(x) { log(-log(x)) }
par(family = "Latin Modern Roman 10", mar = c(5.1, 4.1, 0.5, 2.1))
gehan.cox1 <- coxph(Surv(time, event = cens) ~ 1, data = gehan[gehan$treat=="control", ])
gehan.cox2 <- coxph(Surv(time, event = cens) ~ 1, data = gehan[gehan$treat=="6-MP", ])
gehan.S1<- survfit(gehan.cox1)
gehan.S2<- survfit(gehan.cox2)
plot(gehan.S1, ylab= "log(–log(S(t)))", xlab = "Time", fun = logmlog, conf.int = FALSE, xlim = range(gehan$time), lty = 2)
lines(gehan.S2, fun = logmlog, conf.int = FALSE, lty = 1)
legend("bottomright", lty = c(2, 1), legend = c("Control", "6-MP"), cex = 0.8)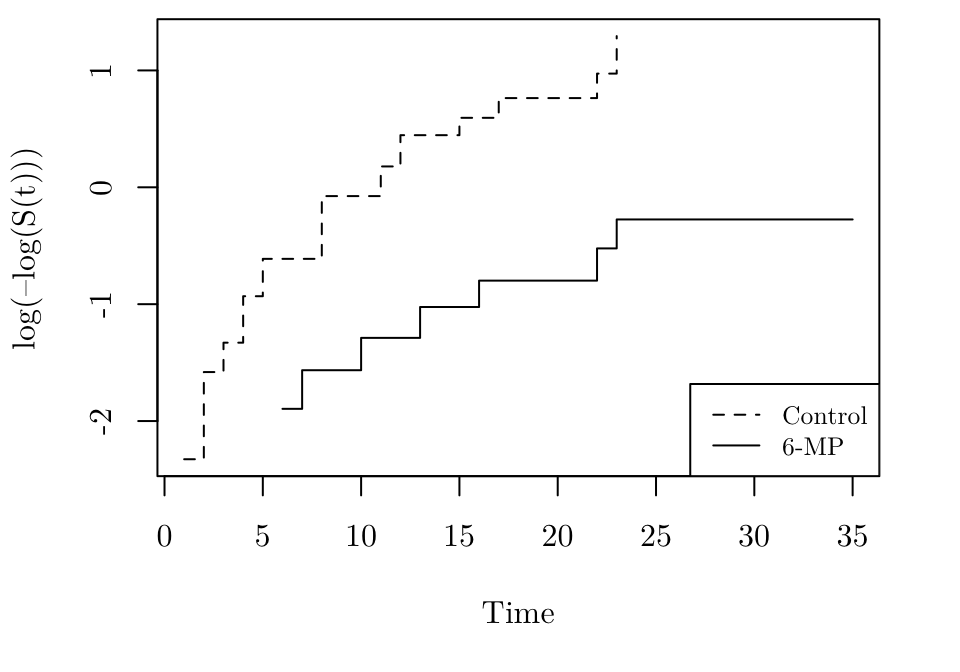
Checking proportional hazards
The following R code produces the plot for the leuk dataset, where \(x_j\) corresponds to ag.
logmlog <- function(x) { log(-log(x)) }
par(family = "Latin Modern Roman 10", mar = c(5.1, 4.1, 0.5, 2.1))
leuk.cox1 <- coxph(Surv(time) ~ log(wbc), data = leuk[leuk$ag == "absent", ])
leuk.cox2 <- coxph(Surv(time) ~ log(wbc), data = leuk[leuk$ag == "present", ])
leuk.S1 <- survfit(leuk.cox1, newdata = data.frame(wbc = mean(leuk$wbc)))
leuk.S2 <- survfit(leuk.cox2, newdata = data.frame(wbc = mean(leuk$wbc)))
plot(leuk.S1, ylab = "log(–log(S(t)))", xlab = "Time", fun = logmlog, conf.int = FALSE, xlim = range(leuk$time), lty = 1)
lines(leuk.S2, fun = logmlog, conf.int = FALSE, lty = 2)
legend("bottomright", lty = c(1,2), legend = c("Absent","Present"), cex = 0.8)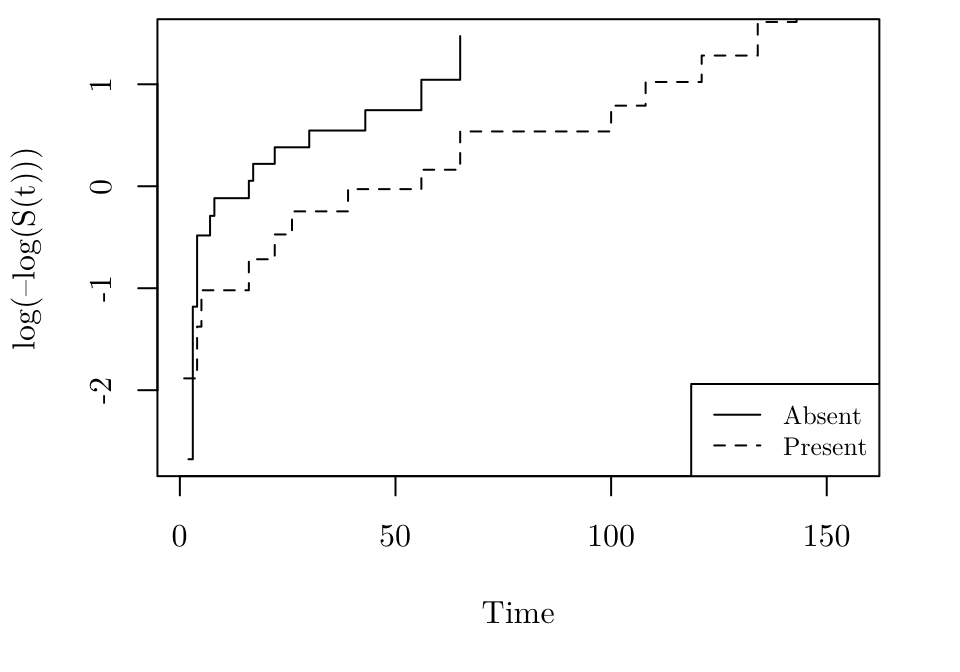
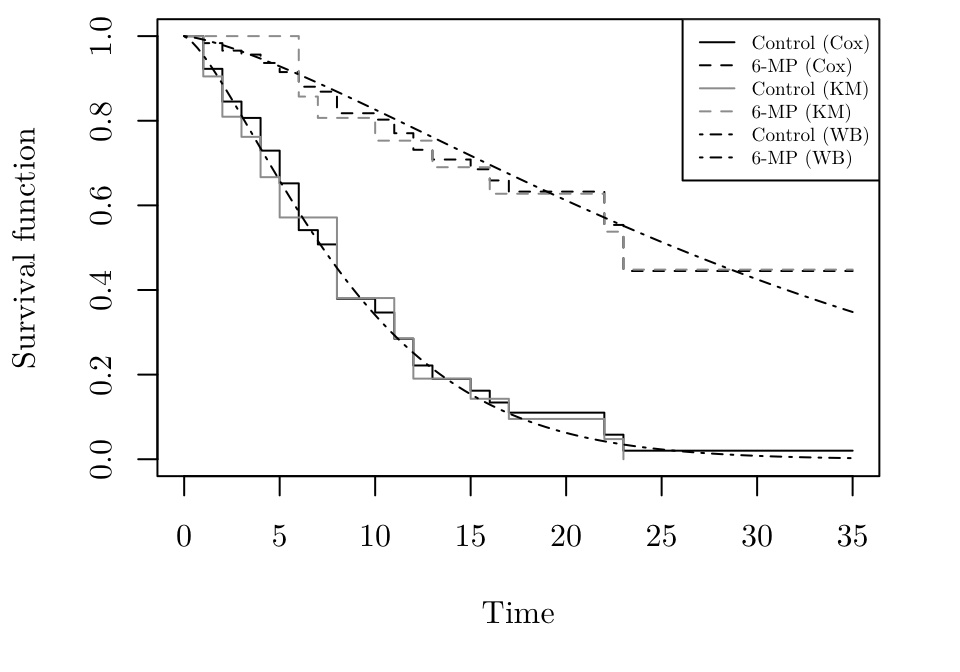
Example: Weibull AFT model (gehan)
The following R code plots the estimated Kaplan-Meier and Cox survival curves. It then adds estimated survival curves from the Weibull model using the curve function.
par(family = "Latin Modern Roman 10", mar = c(5.1, 4.1, 0.5, 2.1))
gehan.wb <- survreg(Surv(time, event = cens) ~ treat, data = gehan)
alpha <- (1 / gehan.wb$scale)
theta.control <- exp(-gehan.wb$coefficients[1] - gehan.wb$coefficients[2])
theta.6MP <- exp(-gehan.wb$coefficients[1])
plot(gehan.S, ylab = "Survival function", xlab = "Time", lty = c(1,2))
lines(gehan.km, lty = c(2, 1), col = 8)
curve(expr = exp(-(theta.control * x) ^ alpha), from = 0, to = 35, add = TRUE, lty = 4)
curve(expr = exp(-(theta.6MP * x) ^ alpha), from = 0, to = 35, add = TRUE, lty = 4)
legend("topright", lty = c(1, 2, 1, 2, 4, 4), col = c(1, 1, 8, 8, 1, 1), legend = c("Control (Cox)", "6-MP (Cox)", "Control (KM)", "6-MP (KM)", "Control (WB)", "6-MP (WB)"), cex = 0.6)