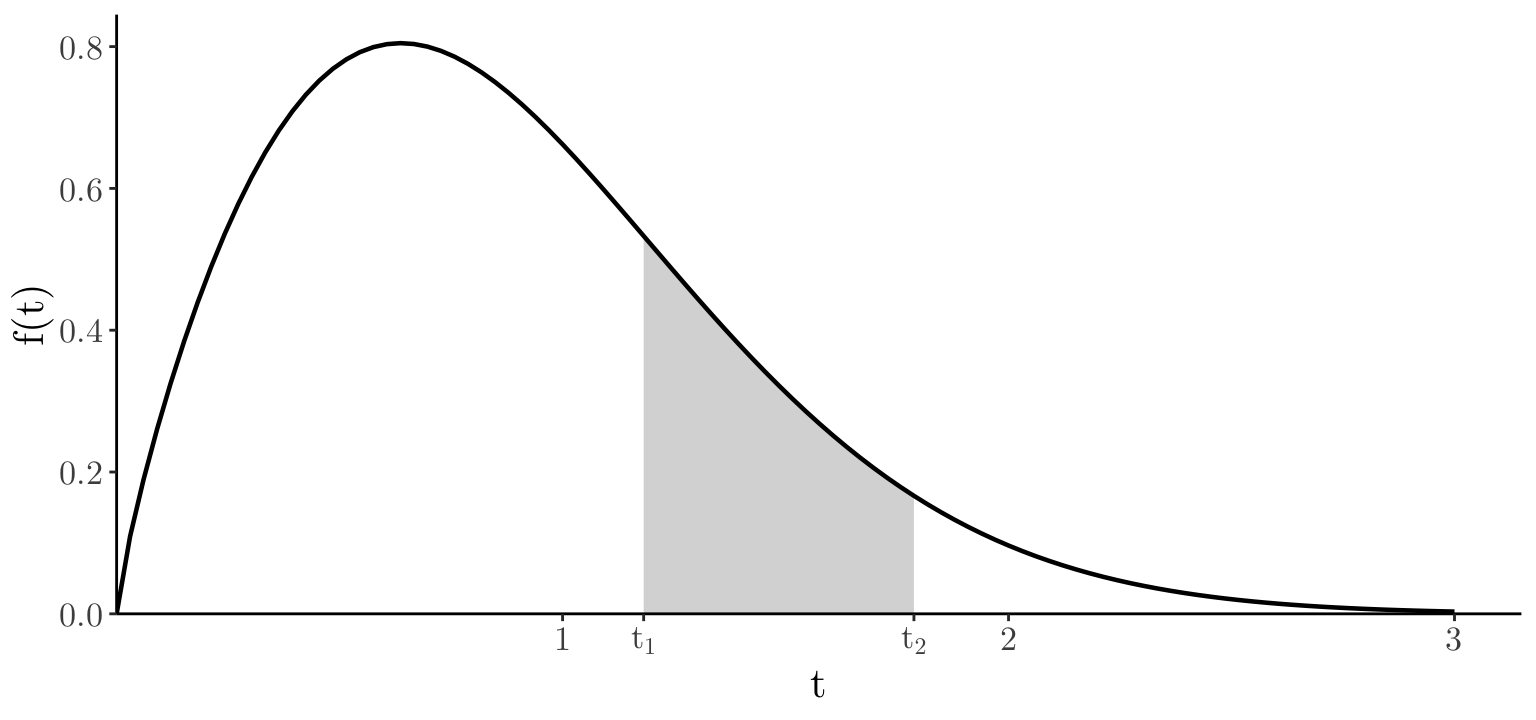
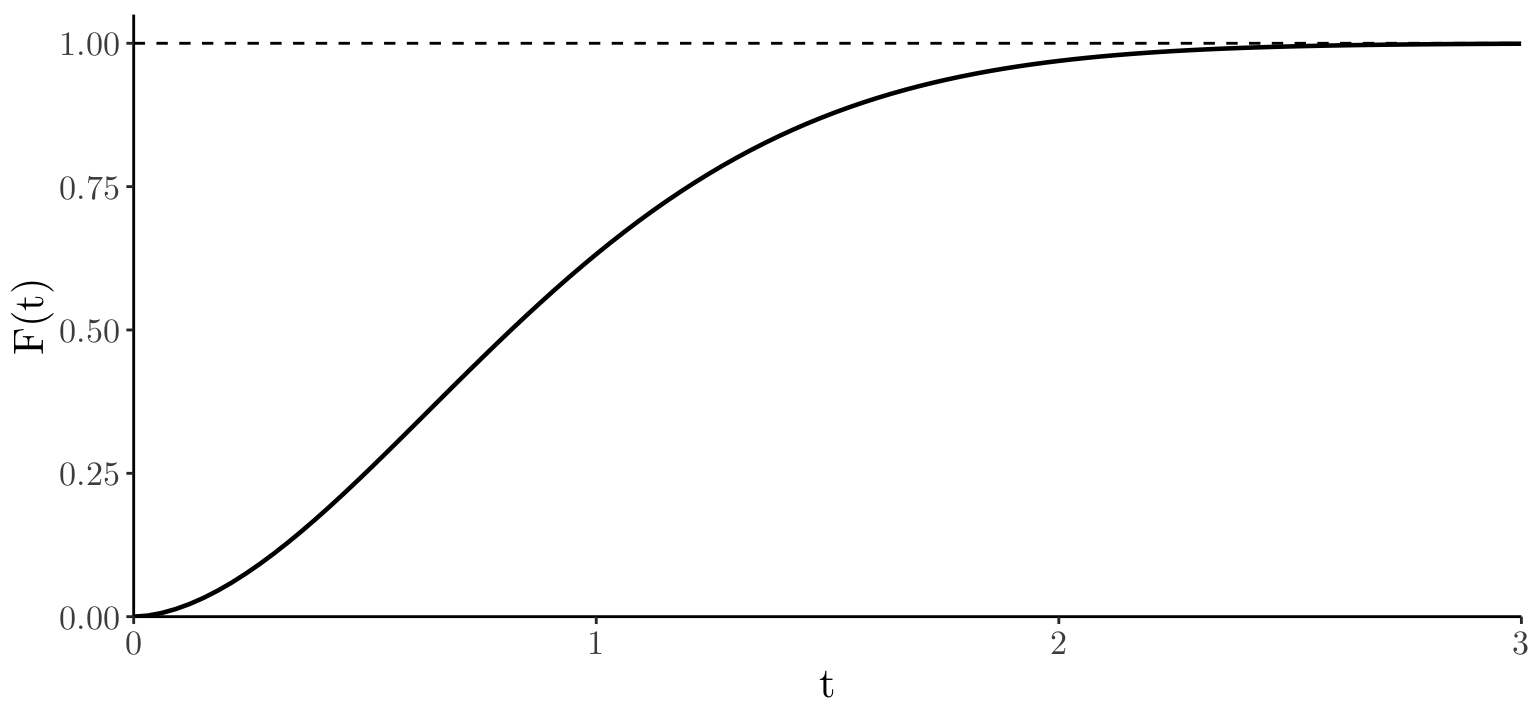
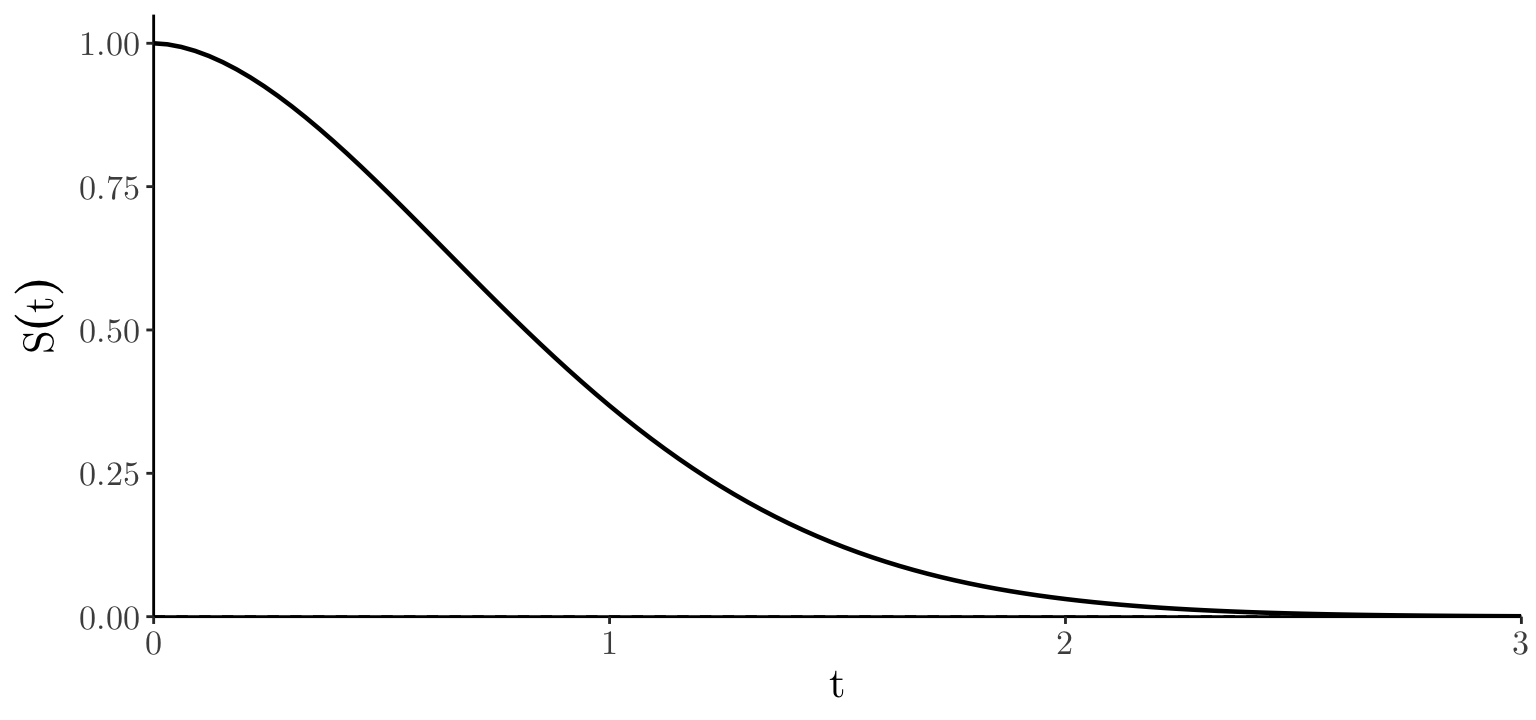
x_seq <- seq(0, 3, length = 100); df <- data.frame(t = x_seq, ft = dweibull(x_seq, 1.8, 1))
t1_val <- df[['t']][40]; t2_val <- df[['t']][60]
df_shade <- filter(df, t >= t1_val & t <= t2_val); poly_data <- data.frame(t = c(t1_val, df_shade[['t']], t2_val), ft = c(0, df_shade[['ft']], 0))
ggplot(df, aes(x = t, y = ft)) +
geom_polygon(data = poly_data, fill = "gray", alpha = 0.6) +
geom_line(linewidth = 0.8) +
theme_bw() +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), panel.border = element_blank(), axis.line.x = element_line(linewidth = 0.5, color = "black"), axis.line.y = element_line(linewidth = 0.5, color = "black")) +
labs(x = "t", y = "f(t)") +
scale_x_continuous(expand = expansion(mult = c(0, 0.05)), breaks = c(1, t1_val, t2_val, 2, 3), labels = c(1, expression(t[1]), expression(t[2]), 2, 3)) + scale_y_continuous(expand = expansion(mult = c(0, 0.05))) +
theme(text = element_text(size = 16, family = "Latin Modern Roman 10"))